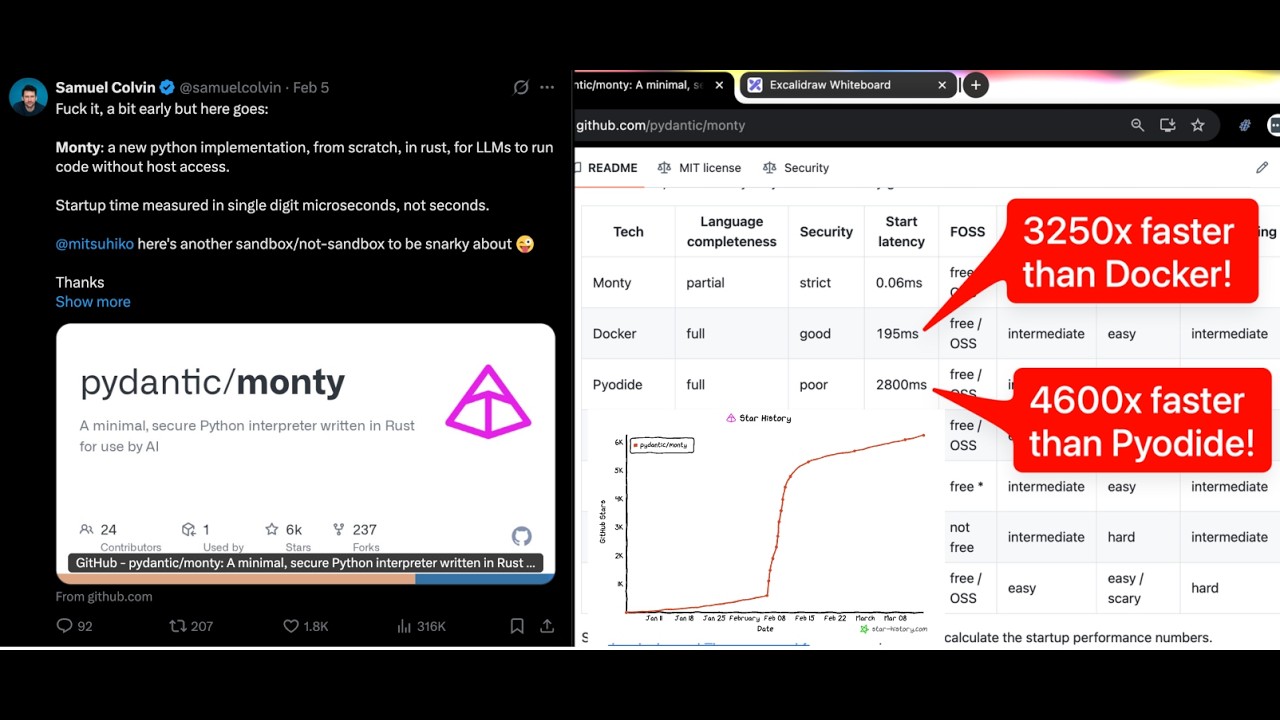
Playground in Prod - Optimising Agents in Production Environments — Samuel Colvin, Pydantic
Samuel Colvin, creator of Pydantic, demonstrates a hands-on workflow for continuously optimizing AI agents in production. The session covers using Logfire for running evaluations, GEPA (Genetic Pareto) for autonomously evolving better prompts, and managed variables to deploy these improvements to live services without redeployment.