Why AI Agents Shouldn't Replace Your Fraud Models
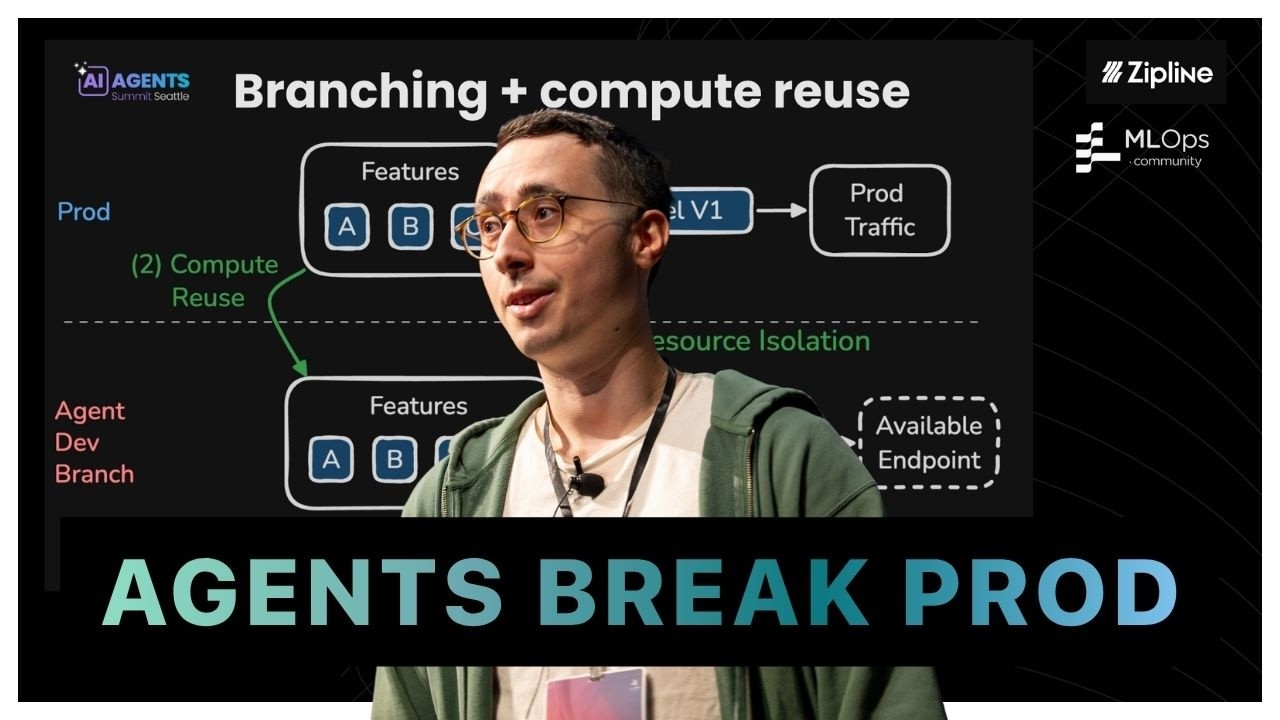
Varant Zanoyan, original author of the Chronon feature platform, introduces 'agentic experimentation'—a pattern where AI agents improve high-stakes ML systems without making live decisions. He explains how Chronon solves key challenges like infrastructure sprawl, safety, and reproducibility through a semantic API, branch-based isolation, and compute reuse, enabling agents to safely create production-ready pipelines for human review.